

Лабораторная работа №6
Линейная регрессия.
1.Цель работы
Ознакомиться с функцией lm() в языке программирования R. Научиться
предсказывать данные, а также представлять результаты в удобном виде.
2.Порядок выполнения работы
•Сгенерируйте набор данных для моделирования, загрузите свой набор данных или воспользуйтесь одним из встроенных наборов в R.
Каждый студент должен работать со своим набором данных, приведенным ниже в зависимости от порядкового номера (второй столбец таблицы – пакет::название набора данных);
•Постройте график pairs.panels(dataframe) из пакета psych,
который показывает как распределены значения переменных между собой попарно, найдите несколько независимых и зависимую переменную к которым можно применить линейную регрессию, между которыми наблюдается тесная связь, это будут данные с которыми Вы будете работать далее. Пример продемонстрирован на рисунке 1.
Рисунок 1 – Найдена взаимосвязь между переменными x2 и y

• Постройте график зависимости зависимой и независимой переменной, можно использовать стандартную функцию plot().
Рисунок 2 – График зависимости зависимой (mpg) и независмой (hp)
переменных
•Примените линейную регрессию к данным с помощью lm().
Выведите summary() получившегося результата.
• Далее сгенерируйте новый data.frame, состоящий из одной зависимой переменной. Длина этой переменной должна совпадать с длиной в исходных данных. Заполните, например, от 0 … nrow() (зависит от данных).
Затем примените функцию predict(данные после lm, новый data.frame).
Пример выполнения:
points_to_predict <- data.frame(hp = c(00:230))
prediction <- predict(dannie.mpg, newdata = points_to_predict)
•Затем отобразите предсказанные данные на графике из рисунка
2.Это можно сделать с помощью функции lines(points_to_predict$hp,
prediction, col = …). Пример представлен на рисунке 3.
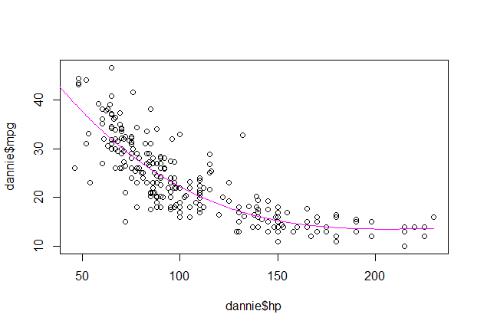
Рисунок 3 – Пример выполнения
•В примере на рисунке 3 представлена наилучший вариант для линейной регрессии. Пробуйте улучшать свою модель, получаемую при выполнении функции lm(), путем использования для независимой переменной функции poly(независимая переменная, степень). Добейтесь лучшего варианта для Вашего графика.
•До этого момента мы работали с одной зависимой и одной независимой переменными. Теперь давайте проделаем все то же самое, но с использованием нескольких независимых переменных. Для улучшения параметров модели Вам может пригодится функция polym(), где для корректной работы обычно необходимо установить аргумент raw = T.
Пример выполнения:
dannie.second <- lm(mpg ~ polym(hp,cylinders,degree=3,raw=TRUE),data = dannie)
• Здесь мы не будем использовать функцию predict, а лишь отобразим график зависимая/независимые переменные с добавлением линии
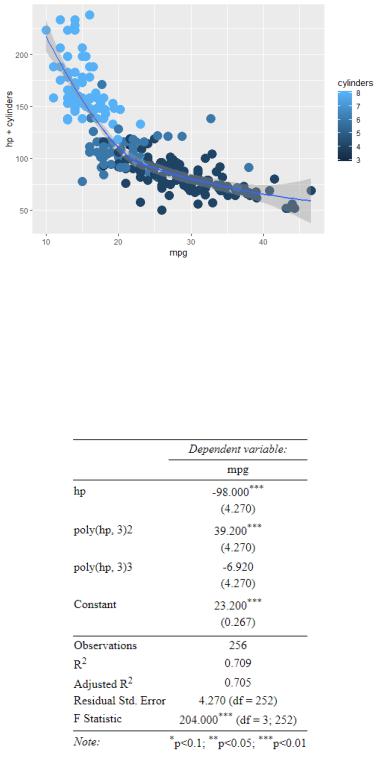
регрессии с доверительными интервалами. Для этого будем использовать пакет ggplot2. Функция построения ggplot, а также Вам понадобятся geom_point() и geom_smooth(). Пример итогового графика:
Рисунок 4 – Пример выполнения
• После каждого выполнения lm() мы выводили summary() – эти данные можно экспортировать из R в очень удобном для представления в отчете виде. Ознакомьтесь с пакетом stargazer. Пример представления summary в отчете.
Рисунок 5 – Наглядное представление summary от lm
3. Содержание отчета
1.Цель работы.
2.Описание и результаты выполнения работы, а также графики и наглядное представление summary по каждой линейной модели.
3.Выводы о проделанной работе.
Датасеты по вариантам:
1 |
datasets::airquality |
|
|
2 |
boot::melanoma |
|
|
3 |
datasets::swiss |
|
|
4 |
carData::Baumann |
|
|
5 |
carData::BEPS |
|
|
6 |
carData::CES11 |
|
|
7 |
carData::Chile |
|
|
8 |
carData::GSSvocab |
|
|
9 |
carData::KosteckiDillon |
|
|
10 |
ggplot2::diamonds |
|
|
11 |
DAAG::cps2 |
|
|
12 |
DAAG::frogs |
|
|
13 |
DAAG::leafshape |
|
|
14 |
Ecdat::BudgetUK |
|
|
15 |
Ecdat::Hmda |
|
|
16 |
Ecdat::Irates |
|
|
17 |
Ecdat::MCAS |
|
|
18 |
ggplot2::midwest |
|
|
19 |
ggplot2::mpg |
|
|