

ГУАП
КАФЕДРА №41
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
ассистент |
|
|
|
В.В. Боженко |
|
|
|
|
|
|
|
|
|
|
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ №1
ПРЕДВАРИТЕЛЬНЫЙ АНАЛИЗ ДАННЫХ
по курсу: Введение в анализ данных
РАБОТУ ВЫПОЛНИЛ
СТУДЕНТ ГР. №
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург 2022

Цель работы
Осуществить предварительную обработку данных csv-файла, выявить и
устранить проблемы в этих данных.
Индивидуальный вариант
Индивидуальный вариант номер 10 в соответствии с таблицей 1.
|
|
Таблица 1 – Индивидуальный вариант задания |
|
|
|
Название |
|
Пояснение |
датафрейма |
|
|
|
|
|
10estate_data.csv Содержится информация о продажах квартир: |
||
1. |
число фотографий квартиры в объявлении |
|
2. |
цена на момент снятия с публикации |
|
3. |
площадь квартиры в квадратных метрах (м²) |
|
4. |
дата публикации |
|
5. rooms — число комнат |
||
6. |
высота потолков (м) |
|
7. |
всего этажей в доме |
|
8. |
жилая площадь в квадратных метрах (м²) |
|
9. |
этаж |
|
10. |
апартаменты (булев тип) |
|
11. |
квартира-студия (булев тип) |
|
12. |
свободная планировка (булев тип) |
|
13. |
площадь кухни в квадратных метрах (м²) |
|
14. |
число балконов |
|
15. |
название населённого пункта |
|
16. |
расстояние до ближайшего аэропорта в метрах (м) |
|
17. |
расстояние до центра города (м) |
|
18. |
число парков в радиусе 3 км |
|
19. |
расстояние до ближайшего парка (м) |
|
20. |
число водоёмов в радиусе 3 км |
|
21. |
расстояние до ближайшего водоёма (м) |
|
22. |
сколько дней было размещено объявление (от |
|
публикации до снятия) |
||
Группировки, которые можно сделать:
-цена за метр по этажам
-средняя цена по количеству комнат и тд
2
Ход работы
1)Получили у преподавателя набор данных 10estate_data.csv в соответствии с индивидуальным вариантом №10 для проведения анализа согласно цели выполняемой работы.
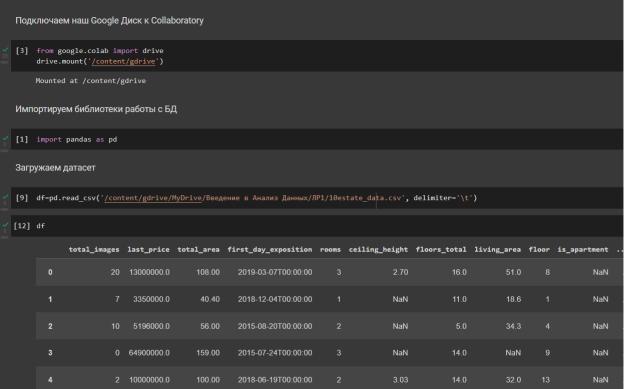
2)Загрузить датасет с помощью библиотеки pandas в Jupyter-
ноутбуке в соответствии с рисунком 1.
Рисунок 1 – Загрузка датаcета в Colab из файла 10estate_data.csv на Google Диске
3
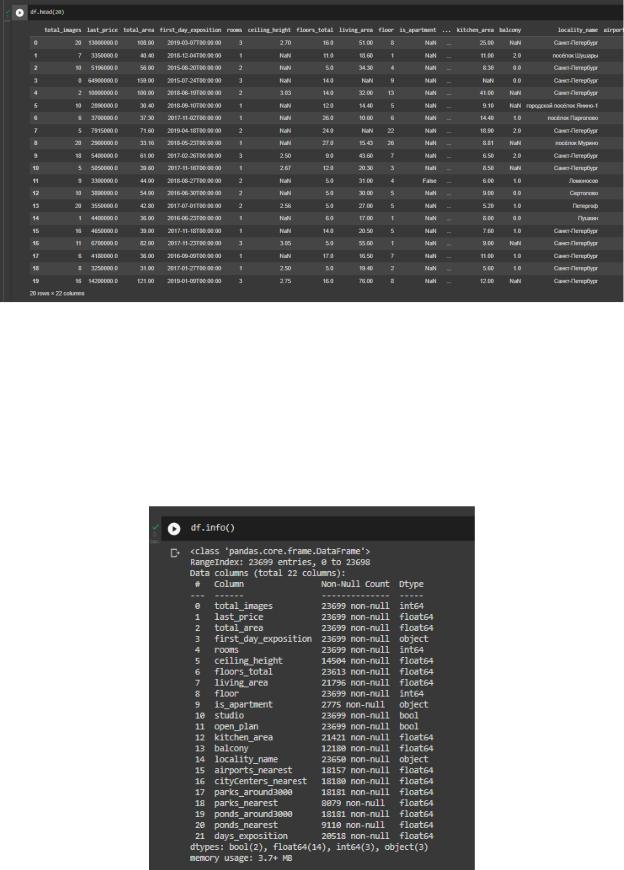
3) Вывели первые 20 строк с помощью head в соответствии с рисунком 2.
Рисунок 2 – Первые 20 строк дата сета
4) Выполнили обзор данных с пояснениями по содержимому каждого столбца в соответствии с таблицей 1.
С помощью метода .info оценили данные (№ столбца, название колонки, кол-во не пустых значений в столбце, тип данных) в соответствии с рисунком 3.
Рисунок 3 – Информация о данных
4

5) Вывели на экран названия столбцов с помощью df.columns в
соответствии с рисунком 4.
Рисунок 4 – Список столбцов датасета Выявили следующие проблемы с названиями: не все названия в змеином
регистре (cityCenters_nearest, parks_around3000, ponds_around3000), по некоторым названиям сложно пониять что содержат столбцы (rooms, balcony).
Из плюсов все названия написаны на английском языке без пробелов.
Устранили проблемы с помощью df.rename в соответствии с рисунком 5.
Рисунок 5 – Устранение проблем с названиями столбцов
5

6) Выявили пропуски с помощью df.isna().sum() в соответствии с рисунком 6.
Рисунок 6 – Кол-во пропусков значений в столбцах датасета Так как цель исследования, для которого нужны данные не указана в
лабораторной работе постараемся сохранить максимальное количество строк исходного датасета.
Для того чтобы устранить пропуски изучили модель данных и решили следующее:
• Столбец «ceiling_height» (6. высота потолков (м)) заменим на среднее значение для столбца. Код в соответствии с рисунком 7;
Рисунок 7 – Код устранения пропусков для столбца «ceiling_height»
• Столбец «floors_total» (7. всего этажей в доме) можно удалить строки так как их не так много. Код в соответствии с рисунком 8;
Рисунок 8 – Код устранения пропусков для столбца «floors_total»
6

• Столбец «living_area» (8. жилая площадь в квадратных метрах (м²)) заменим на среднее значение для сторок со схожей площадью квартир (разницы ±5% метров). Код в соответствии с рисунком 9;
Рисунок 9 – Код устранения пропусков для столбца «living_area»
•Столбец «is_apartment» (10. апартаменты (булев тип)) заменить
NAN на False, так как можно предположить, что квартира не является апартаментами. Код в соответствии с рисунком 10;
Рисунок 10 – Код устранения пропусков для столбца «is_apartment»
• Столбец «kitchen_area» (13. площадь кухни в квадратных метрах (м²)) заменим на среднее значение для строк со схожей площадью квартир (разницы ±10% метров). Код в соответствии с рисунком 11;
Рисунок 11 – Код устранения пропусков для столбца «kitchen_area»
•Столбец «balcony_count» (14. число балконов) заменить NAN на 0,
так как можно предположить, что в квартире нет балконов. Код в соответствии с рисунком 12;
Рисунок 12 – Код устранения пропусков для столбца «balcony_count»
•Столбец «locality_name» (15. название населённого пункта)
данные строки придется удалить, потому что эта информация о квартирах имеет большое значение. Код в соответствии с рисунком 13;
Рисунок 13 – Код устранения пропусков для столбца «locality_name»
7

• Столбец «airports_nearest» (16. расстояние до ближайшего аэропорта в метрах (м)) заменить NAN на 0, так как эта информация не столь важна и можно предположить, что в населенном пункте, где расположена квартира нет аэропорта. Код в соответствии с рисунком 14;
Рисунок 14 – Код устранения пропусков для столбца «airports_nearest»
• Столбец «city_centers_nearest» (17. расстояние до центра города (м)) заменить NAN на 0, так как эта информация не столь важна и можно предположить, что квартира либо находится в центре, либо как такового центра в населенном пункте нет. Код в соответствии с рисунком 15;
Рисунок 15 – Код устранения пропусков для столбца «city_centers_nearest»
•Столбец «parks_around_3000» (18. число парков в радиусе 3 км)
заменим NAN на 0, так как эта информация не столь важна и можно предположить, что парков в радиусе 3 км нет. Код в соответствии с рисунком 16;
Рисунок 16 – Код устранения пропусков для столбца «parks_around_3000»
• Столбец «parks_nearest» (19. расстояние до ближайшего парка (м)) заменим NAN на 0, так как эта информация не столь важна и можно предположить, что парков в радиусе 3 км нет. Код в соответствии с рисунком 17;
Рисунок 17 – Код устранения пропусков для столбца «parks_nearest»
8
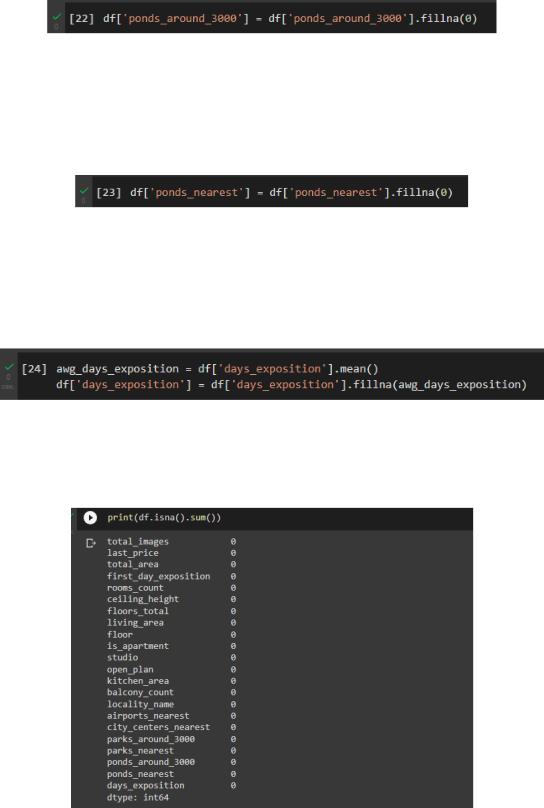
•Столбец «ponds_around_3000» (20. число водоёмов в радиусе 3 км)
заменим NAN на 0, так как эта информация не столь важна и можно предположить, что водоемов в радиусе 3 км нет. Код в соответствии с рисунком 18;
Рисунок 18 – Код устранения пропусков для столбца «ponds_around_3000»
• Столбец «ponds_nearest» (21. расстояние до ближайшего водоёма (м)) заменим NAN на 0, так как можно предположить, что водоемов в радиусе 3 км нет. Код в соответствии с рисунком 19;
Рисунок 19 – Код устранения пропусков для столбца «ponds_nearest»
• Столбец «days_exposition» (22. сколько дней было размещено объявление (от публикации до снятия)) заменим на среднее значение для столбца, так мы не потеряем часть данных. Код в соответствии с рисунком 20.
Рисунок 20 – Код устранения пропусков для столбца «days_exposition»
Результат решения проблемы пропусков в строках датасета в соответствии с рисунком 21.
Рисунок 21 – Результат устранения пропусков в данных
9
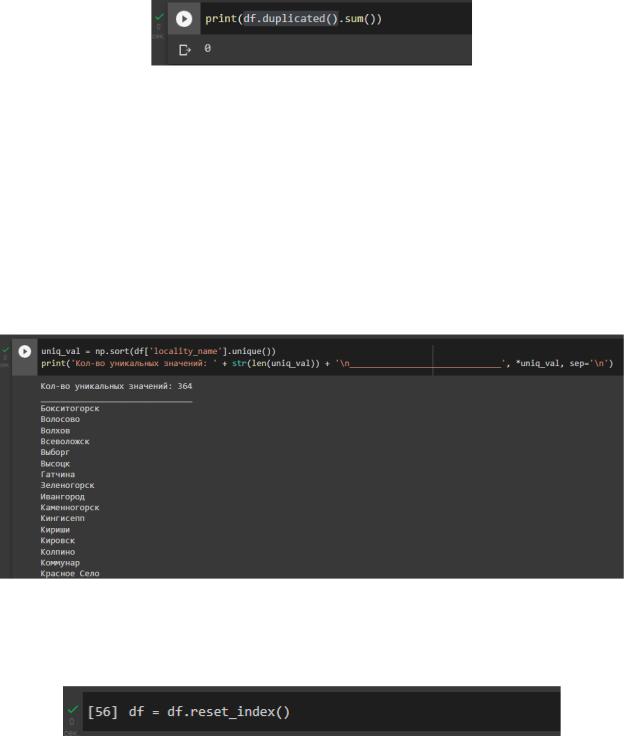
7)Проверили данные на наличие дубликатов.
Проверили явные дубликаты с помощью функции, их не оказалось. duplicated() в соответствии с рисунком 22.
Рисунок 22 – Поиск явных дубликатов Поиск неявных дубликатов. Так как практически все столбцы содержат
числа или даты или булевы значения, то имеет смысл проверить единственный содержащий строковые значения столбец «locality_name» на наличие различных написаний одного и того же значения. Для этого воспользовались функцией .unique() результат отсортировали для удобства проверки.
Просмотрев все значения, различных написаний не обнаружили. Код и результат в соответствии с рисунком 23.
Рисунок 23 – Поиск неявных дубликатов После устранения проблем пропусков и дубликатов обновили индексы с
помощью функции reset_index() в соответствии с рисунком 24.
Рисунок 24 – Обновление индексов в датафрейме
10