

Дополнительная литература 81
встречающиеся в них обоих. На основе этой информации можно вычислить коэффициент Жаккара .
Обновляем словарь jacard_by_author и выводим каждый результат в окне интерпретатора. Затем находим автора с максимальным значением Жаккара и выводим результаты.
Коэффициент сходства Жаккара для doyle = 0.34847801578354004 Коэффициент сходства Жаккара для wells = 0.30786921307869214 Наиболее вероятным автором по схожести является doyle
В итоге счет оказывается в пользу Дойла.
Завершаем stylometry.py кодом для выполнения программы в качестве импортируемого модуля или в автономном режиме.
Итоги
Истинный автор «Затерянного мира» — Дойл. Установив это, мы останавливаемся и объявляем победу. Если вы хотите провести дополнительные исследования, то можете в качестве следующего теста добавить другие известные тексты к doyle
иwells, чтобы их совмещенная длина была ближе к тексту «Затерянного мира»
ине пришлось его слишком обрезать. Можно также протестировать длину предложений и стиль пунктуации или применить более сложные техники, такие как нейронные сети и генетические алгоритмы.
Помимо этого, иногда полезно доработать существующие функции, например vocab_test() и jaccard_test(), техниками стемминга и лемматизации, чтобы сократить слова до их корневых форм для лучшего сравнения. В том виде, в каком сейчас написана программа, talk, talking и talked рассматриваются как совершенно разные слова, несмотря на общий корень.
И все же стилометрия не может с абсолютной достоверностью гарантировать, что именно сэр Артур Конан Дойл написал «Затерянный мир». Она может лишь предположить на основе весомых свидетельств, что он более вероятный автор, нежели Уэллс. Здесь очень важна формулировка вопроса, поскольку нельзя оценить всех возможных авторов. По этой причине успешное определение авторства начинается со старой доброй детективной работы, которая сокращает список кандидатов до приемлемой длины.
Дополнительная литература
«Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit» (O’Reilly, 2009) Стивена Берда (Steven Bird), Эвана Клейна

82 Глава 2. Установление авторства с помощью стилометрии
(Ewan Klein) и Эдварда Лопера (Edward Loper)1 представляет доступное введение в область NLP при помощи Python со множеством упражнений и полезной интеграцией с сайтом NLTK. Новая версия книги, обновленная для Python 3 и NLTK 3, доступна онлайн на http:www.nltk.org/book/.
В 1995 году романист Курт Воннегут высказал идею, что «истории имеют формы, которые можно нарисовать на миллиметровой бумаге», и предложил «передать их на обработку компьютерам». В 2018 году энтузиасты реализовали его идею, использовав более 1700 английских романов. Они применили NLPтехнику анализа тональности текста, которая распознает присущий словам эмоциональный окрас. Полученные результаты описаны в книге «Every Story in the World Has One of These Six Basic Plots», которую можно найти на сайте BBC.com по ссылке http://www.bbc.com/culture/story/20180525-every-story-in-the- world-has-one-of-these-six-basic-plots/.
Практический проект: охота на собаку Баскервилей с помощью распределения
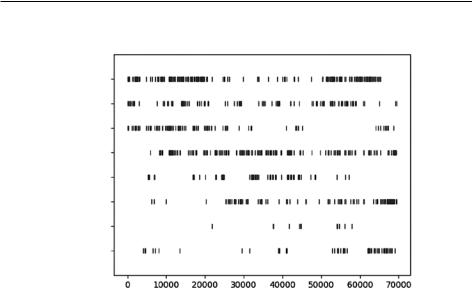
В NLTK есть небольшая занятная функция, называемая диаграммой распределения, которая позволяет определить местоположение слова в тексте. Если конкретнее, то она составляет диаграмму вхождений слова относительно количества предшествующих ему слов с начала корпуса.
На рис. 2.7 показана диаграмма распределения упоминания главных персонажей в книге «Собака Баскервилей».
Если вы знакомы с этой историей — а если нет, то спойлерить я ее не стану, — то согласитесь с редким упоминанием Холмса в середине, практически двухполярным распределением вхождений Мортимера и возникшим под конец рассказа пересечением упоминаний о Бэрриморе, Сэлдене и собаке Баскервилей.
Диаграммы распределения имеют и более практическое применение. Например, как автор технической литературы, я должен давать определение новому термину при его первичном появлении в книге. Звучит это просто, но иногда главы пишутся не по порядку, и подобные нюансы проскакивают незамеченными. Диаграмма распределения, построенная для списка технических терминов, если их много, может существенно упростить поиск места их первого упоминания.
1Эта книга не издавалась на русском языке, но можно порекомендовать другие издания, имеющие высокий рейтинг: Бенгфорт Б., Ребекка Билбро Р., Тони Охеда Т. «Прикладной анализ текстовых данных на Python. Машинное обучение и создание приложений обработки естественного языка» или Хобсон Л., Ханнес Х., Коул Х. «Обработка естественного языка в действии», обе — издательство «Питер». — Примеч. ред.
Практический проект: тепловая карта пунктуации 83
Д а а а а
Х
Ва
М
Г
Б
С
С
С а а
С а
Рис. 2.7. График распределения упоминания главных персонажей в книге «Собака Баскервилей»
Или вот другой вариант. Представьте, что вы — аналитик данных и работаете с ассистентами адвоката по уголовному делу, связанному с торговлей внутренней информацией компании. Для выяснения, говорил ли обвиняемый с конкретным членом правления как раз перед совершением незаконной продажи, вы можете загрузить истребованные электронные письма обвиняемого в виде непрерывной строки и сгенерировать диаграмму распределения. Если имя члена правления появится в ожидаемом месте, то дело можно считать решенным!
Для этого практического проекта напишите на Python программу, воссоздающую диаграмму распределения с рис. 2.7. Если у вас возникнут проблемы с загрузкой корпуса hound.txt, обратитесь еще раз к обсуждению Юникода на с. 66. Решение под названием practice_hound_dispersion.py вы найдете в приложении к книге или онлайн.
Практический проект: тепловая карта пунктуации
Тепловая карта — это диаграмма, в которой значения данных представляются с помощью цвета. Тепловые карты используются для визуализации особенностей авторской пунктуации (https://www.fastcompany.com/3057101/the-surprising- punctuation-habits-of-famous-authors-visualized/) и могут оказаться полезными при установлении авторства «Затерянного мира».

84 Глава 2. Установление авторства с помощью стилометрии
Напишите программу Python, токенизирующую три рассмотренные в этой главе книги на основе только пунктуации. Далее сосредоточьтесь исключительно на использовании точек с запятой. Для каждого автора составьте тепловую карту, отображающую точки с запятыми синим, а все остальные знаки препинания — желтым или красным. На рис. 2.8 показаны примеры тепловых карт для «Войны миров» Уэллса и «Собаки Баскервилей» Дойла.
Рис. 2.8. Тепловая карта использования точек с запятой (темные квадраты) Уэллсом (слева) и Дойлом (справа)
Сравните эти три тепловые карты. За чьим авторством, согласно результатам, был написан роман «Затерянный мир» — Дойла или Уэллса?
Решение под названием practice_heatmap_semicolon.py вы найдете в приложении к книге или онлайн.
Усложняем проект: фиксирование частотности
Как уже ранее отмечалось, частотность в NLP означает количество, но также может быть выражена в виде числа вхождений за единицу времени. Еще она выражается как соотношение или процент.
Определите новый вариант метода nltk.FreqDist(), который вместо количеств будет использовать проценты, и задействуйте его для формирования графиков в программе stylometry.py. За помощью можете обратиться к блогу Clearly Erroneous на https://martinapugliese.github.io/tech/plotting-the-actual-frequencies-in- a-FreqDist-in-nltk/.