

Преобразованная матрица стандартизованных рангов
Показатели |
Специалисты |
Ri |
i |
|
i |
|||||||||
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|||||
1 |
3,5 |
2 |
5,5 |
1 |
4,5 |
2 |
6 |
1 |
5,5 |
2 |
33 |
-2 |
4 |
0,16 |
2 |
5 |
1 |
3,5 |
4 |
2 |
1 |
3,5 |
2,5 |
3,5 |
1 |
27 |
-8 |
64 |
0,13 |
3 |
6 |
4 |
5,5 |
2,5 |
6 |
4 |
5 |
2,5 |
5,5 |
3 |
44 |
9 |
81 |
0,21 |
4 |
1 |
6 |
1,5 |
6 |
2 |
6 |
1 |
6 |
2 |
6 |
37,5 |
2,5 |
6,25 |
0,18 |
5 |
2 |
4 |
3,5 |
5 |
4,5 |
4 |
2 |
5 |
3,5 |
4,5 |
38 |
3 |
9 |
0,18 |
6 |
3,5 |
4 |
1,5 |
2,5 |
2 |
4 |
3,5 |
4 |
1 |
4,5 |
30,5 |
-4,5 |
20,25 |
0,15 |
Тj |
0,5 |
2 |
1,5 |
0,5 |
0,5 |
2 |
0,5 |
0,5 |
1 |
0,5 |
210 |
35 |
184,5 |
|
Коэффициент конкордации W=0,11; критерий Пирсона хи-квадрат 2расч = 5,59 меньше табличного значения 2табл = 11,07 при уровне значимости = 0,05. Следовательно, согласованность оценок экспертов низкая. Рассчитаем парные коэффициенты ранговой корреляции Спирмена:
Ранговая корреляция Спирмена |
|||||||||
эксперты |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
1 |
-0,58 |
0,61 |
-0,60 |
0,39 |
-0,58 |
0,72 |
-0,74 |
0,52 |
-0,75 |
2 |
|
-0,51 |
0,52 |
-0,03 |
1,00 |
-0,62 |
0,80 |
-0,44 |
0,95 |
3 |
|
|
-0,61 |
0,84 |
-0,51 |
0,79 |
-0,79 |
0,98 |
-0,67 |
4 |
|
|
|
-0,41 |
0,52 |
-0,96 |
0,87 |
-0,49 |
0,57 |
5 |
|
|
|
|
-0,03 |
0,53 |
-0,41 |
0,83 |
-0,20 |
6 |
|
|
|
|
|
-0,62 |
0,80 |
-0,44 |
0,95 |
7 |
|
|
|
|
|
|
-0,96 |
0,70 |
-0,72 |
8 |
|
|
|
|
|
|
|
-0,72 |
0,88 |
9 |
|
|
|
|
|
|
|
|
-0,61 |
Оценки 1, 3, 5, 7 и 9-го экспертов согласованы. Оценки 2, 4, 6 и 8-го экспертов также согласованы. Необходимо провести обработку экспертных оценок и проверку их согласованности по группам:
1 группа |
Абсолют. значения |
Относит. значения |
2 группа |
Абсолют. значения |
Относит. значения |
|
объект1 |
25 |
0,24 |
объект1 |
8 |
0,08 |
|
объект2 |
17,5 |
0,17 |
объект2 |
9,5 |
0,09 |
|
объект3 |
28 |
0,27 |
объект3 |
16 |
0,15 |
|
объект4 |
7,5 |
0,07 |
объект4 |
30 |
0,29 |
|
объект5 |
15,5 |
0,15 |
объект5 |
22,5 |
0,21 |
|
объект6 |
11,5 |
0,11 |
объект6 |
19 |
0,18 |
|
W = 0,74 |
КОЭФФИЦИЕНТ КОНКОРДАЦИИ |
W = 0,814 |
||||
χ2=18,58 |
КРИТЕРИЙ ПИРСОНА ХИ-КВАДРАТ |
χ 2= 20,36 |
||||
Для 5%-ного уровня достоверности (вероятность ошибки), при ν = m - 1 = 4 степенях свободы (число оцениваемых факторов без одного) величина 2 = 9,488 (см. табл. 5), то есть 2расч > 2табл. Следовательно, полученная ранжировка статистически значима. Поэтому с вероятностью 95% можно утверждать, что имеется неслучайная согласованность мнений экспертов по ранжировке оцениваемых параметров.
Корреляционно-регрессионный анализ
Корреляционно-регрессионный анализ применяется для определения и выражения формы аналитической зависимости результативного признака y от факторных признаков xi и измерению тесноты корреляционной связи. Основу решения первой задачи корреляционно-регрессионного анализа составляет качественный анализ данной зависимости. Математическим средством ее количественного выражения является метод наименьших квадратов: сумма квадратов отклонений расчетных значений yр, т.е. полученных из выбранного уравнения связи, от фактических значений yф должна быть минимальной
S = (yр - yф)2 min. (4)
При расчете параметров уравнения регрессии для линейной формы связи типа
у = а0 + а1х1 + а2х2 + а3х3 + а4х4
решается система нормальных уравнений:
 y
= а0
+ а1х1
+ а2 х2
+ а3 х3
+ а4 х4
y
= а0
+ а1х1
+ а2 х2
+ а3 х3
+ а4 х4
yх1 = ао х1 + а1 х12 + а2 х2 х1 + а3 х3х1 + а4 х4х1
yх2 = а0 х2 + а1 х1х2 + а2 х22 + а3 х3х2 + а4 х4х2
yх3 = а0 х3 + а1 х1х3 + а2 х2х3 + а3 х32 + а4 х4х3
yх4 = а0 х4 + а1 х1х4 + а2 х2х4 + а3 х3х4 + а4 х42
При проведении качественного анализа необходимо понимать, что корреляция может быть обусловлена непосредственной зависимостью между x и y, общей зависимостью от третьей величины, неоднородностью материала или быть чисто формальной. Причинная зависимость существует, например, между временем работы и стоимостью производственной продукции, между весом станков и их стоимостью, между мощностью предприятия и себестоимостью его продукции.
Корреляция вследствие неоднозначности возникает из-за значительного разброса статистических данных и она полностью исключается проверкой нулевой гипотезы.
Чтобы избежать типичной ошибки - нахождения и расчета беспричинных формальных корреляций, необходимо провести качественный логический экономический анализ. И если причинной связи между факторами не существует, то бессмысленно проводить математическую обработку фактических данных.
При
проведении корреляционного анализа
надо учитывать также, что достоверное
уравнение регрессии можно получить
только при использовании однородного
статистического материала. Выражением
количественной однородности может
служить коэффициент вариации. Величина
коэффициента вариации, служащая границей
между однородностью и неоднородностью
статистической совокупности составляет
0,33. Величина коэффициента вариации ![]() показывает, что совокупность данных
по рассматриваемому признаку неоднородна.
Поэтому необходимо расчленить исходную
неоднородную совокупность на однородные
части (группы). В данном выражении x
- величина среднеквадратического
отклонения,
показывает, что совокупность данных
по рассматриваемому признаку неоднородна.
Поэтому необходимо расчленить исходную
неоднородную совокупность на однородные
части (группы). В данном выражении x
- величина среднеквадратического
отклонения,
![]() - средняя арифметическая величина
исследуемого признака.
- средняя арифметическая величина
исследуемого признака.
После решения системы нормальных уравнений, получения коэффициентов регрессии и уравнения регрессии необходимо рассчитать показатели тесноты связи. Для многофакторной модели и при нелинейной зависимости теснота связи измеряется величиной индекса корреляции, рассчитываемого по формуле
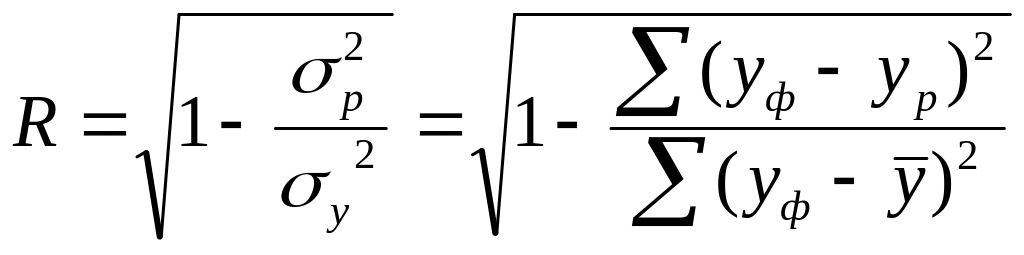 ,
,
где р2 = (yф – yр)2/n, у2 = (yф -y)2/n, yр - значение изучаемого признака, рассчитанного по уравнению регрессии.
Для определения величины индекса корреляции нужно вычислить для каждого реального объекта значение yр по найденному уравнению регрессии. Далее для каждого объекта определяется разность действительного значения yф и вычисленного по уравнению регрессии yр. Сделав это по всем объектам, находят средний квадрат отклонений или остаточную дисперсию вычисленных значений от фактических. Далее определяется средний квадрат отклонения фактических значений признака yф от среднего по изучаемой совокупности того же признака, т.е. общая дисперсия. Полученные величины подставляются в формулу индекса корреляции.
При изучении парной линейной корреляционной зависимости между двумя признаками теснота связи определяется расчетом значения коэффициента корреляции по следующей формуле

где n - число изучаемых объектов в статистической совокупности.
Для качественной оценки тесноты связи может использоваться следующая шкала:
r < 0,3 - слабая связь;
0,3 < r < 0,7 - средняя связь;
0,7 < r < 0,9 - высокая связь;
0,9 < r - весьма высокая связь.
И хотя при малой статистической совокупности можно получить высокую корреляционную связь между изучаемыми признаками, но тем не менее пользоваться полученным уравнением регрессии нельзя из-за его низкой надежности.
При проведении корреляционно-регрессионного анализа производят статистическую оценку значимости коэффициента корреляции и коэффициентов уравнения регрессии. Для этого определяют среднеквадратическую ошибку r коэффициента корреляции (p – число факторных переменных):
![]()
Отношение величины коэффициента корреляции к его среднеквадратической ошибке дает величину t-критерия Стьюдента: t = r/r. Принято считать, что если t > 2, то это свидетельствует о надежности полученного коэффициента корреляции. Вероятность такого утверждения составляет 0,95, и наоборот, если t < 2, это свидетельствует о недостаточной надежности исчисленного коэффициента.
Полученная величина коэффициента корреляции используется для оценки статистической значимости коэффициента уравнения регрессии (аi). Для этого исчисляется его среднеквадратическая ошибка (аi).
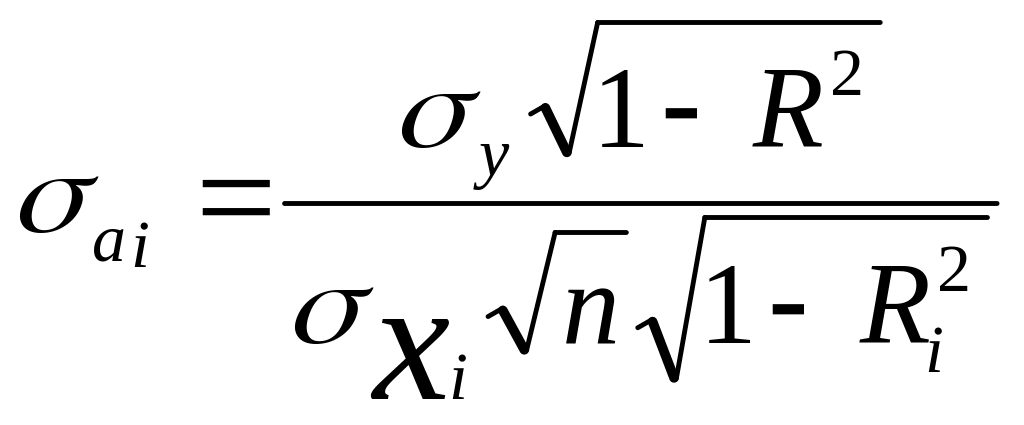 ,
,
 ,
,
где Ri2 – коэффициент множественной корреляции xi-го фактора с другими факторами (без результативного признака у), σxi – среднее квадратическое отклонение xi-го факторного признака.
Коэффициент уравнения регрессии сопоставляется с его среднеквадратической ошибкой. В результате получается отношение tai = ai / аi. Если tai > 2, полученный коэффициент ai следует считать значимым и соответствующий фактор xi остается в уравнении множественной регрессии; если полученный коэффициент нельзя признать значимым (tai < 2), то соответствующий параметр исключается из уравнения множественной регрессии. По оставшемуся набору значимых факторов определяется окончательное уравнение множественной регрессии.
Влияние отдельных факторных признаков на результативный признак в едином масштабе в процентах можно определить по частным коэффициентам эластичности, которые характеризуют, на сколько процентов изменится уровень результативного признака y при изменении xi-го факторного признака на 1 %.
Частный коэффициент эластичности определяется по формуле
Эi = аi (xi / y),
где Эi - частный коэффициент эластичности; аi - коэффициент уравнения множественной регрессии в натуральном масштабе при xi-м факторном признаке;xi - среднее значение xi-го факторного признака;y - среднее значение результативного признака.
Показателем абсолютного отклонения оценок результативного признака является среднеквадратическое отклонение оценок результативного признака, рассчитанных по уравнению регрессии, от их фактических значений, которая определяется по формуле:
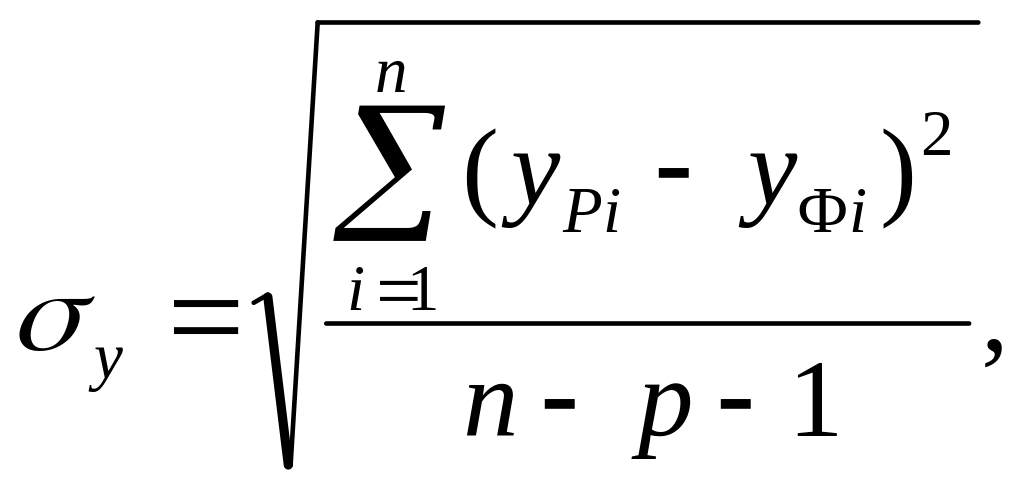
где n - число наблюдений в выборке; р - число факторных признаков модели.
Данная величина используется для определения коэффициента вариации
![]() ,
,
где
![]() -
среднее значение результативного
признака.
-
среднее значение результативного
признака.
Определить предполагаемую величину себестоимости нового изделия на стадии технического задания и технического предложения средствами укрупненного расчета.
Исходные параметры для определения себестоимости электродвигателя: мощность 630 кВт; КПД - 93,7 %; масса 6550 кг; число оборотов в минуту 375.
Статистические данные по продукции аналогичного типа:
Номер изделия |
Мощность, кВт |
КПД, % |
Масса, кг |
Число оборотов в минуту |
Себестоимость, ден.ед. |
1 |
1000 |
95,0 |
4800 |
1000 |
9500 |
2 |
1250 |
95,2 |
5450 |
1100 |
10400 |
3 |
1600 |
95,4 |
7400 |
1000 |
11800 |
4 |
2000 |
95,7 |
8000 |
1000 |
13300 |
5 |
8000 |
94,7 |
4700 |
750 |
9500 |
6 |
1000 |
95,0 |
5250 |
750 |
10400 |
7 |
1250 |
95,2 |
7250 |
750 |
11500 |
8 |
1600 |
95,5 |
7500 |
750 |
13100 |
9 |
630 |
94,5 |
4600 |
750 |
9300 |
10 |
800 |
94,6 |
5160 |
600 |
10300 |
11 |
1000 |
94,6 |
6700 |
600 |
11300 |
12 |
1250 |
94,6 |
7650 |
600 |
12600 |
13 |
1600 |
95,2 |
8900 |
600 |
14300 |
14 |
500 |
93,3 |
5890 |
375 |
10000 |
Примечание: предполагается, что между факторами имеется линейная корреляционная зависимость.
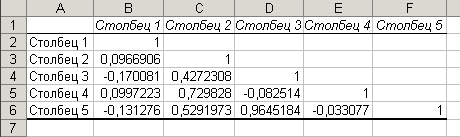
Рис. 12. Парные коэффициенты корреляции
На рис. 12 показан результат расчёт линейных парных коэффициентов корреляции, а на рис. 13 – результаты проведения корреляционно-регрессионного анализа с помощью инструментов Корреляция и Регрессия из пакета Анализ данных электронной таблицы Excel.
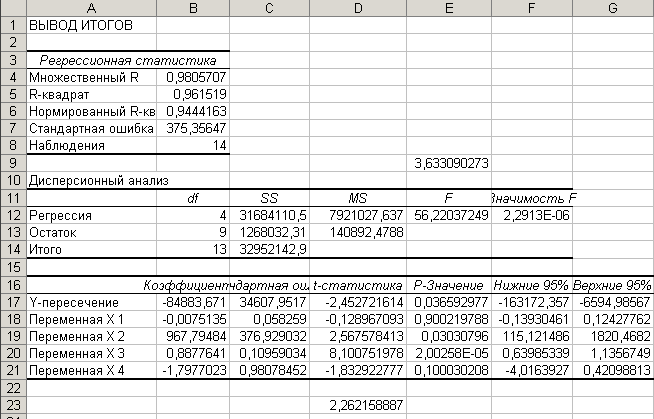
Рис. 13. Результаты корреляционно-регрессионного анализа
В примере предполагается, что на уровень себестоимости продукции (результативный признак - Y) оказывает влияние ряд факторных признаков, таких, например, как мощность (X1), КПД (X2), масса (X3) и число оборотов в минуту (Х4).
Исходя из экономической сущности влияния факторных признаков на результативный, выбираем линейное уравнение регрессии
у = а0 + а1х1 + а2х2 + а3х3 + а4х4.
Данная задача решается на ЭВМ с помощью программы корреляционно-регрессионный анализ. В качестве исходных данных вводятся соответствующие значения факторных признаков и результативного признака по всем исследуемым источникам информации (предприятиям). В результате решения на ЭВМ получаем значения коэффициентов парной корреляции, параметров уравнения регрессии и коэффициента множественной корреляции:
а0 = -15403,631; а1 = 3,1616; а2 = 250,454; а3 = 0,3098;
а4 = -3,729; R = 0,993.
Применяя возможность параметрического расчета на ЭВМ, вводим известные значения параметров для вновь проектируемого изделия, себестоимость которого еще не определена и получаем прогнозное значение Sпр = 10686,4 денежных единицы. При необходимости дальнейшего анализа полученных данных рассчитывается дисперсия, коэффициент вариации, коэффициент эластичности.
Применение корреляционно-регрессионного анализа для прогнозирования динамики экономических явлений. Прогнозирование осуществляется на основе собранных числовых статистических данных, характеризующих изменение экономических процессов или явлений. Такие числовые данные в виде конкретных показателей, изменяющихся во времени, образуют ряд динамики или временной (динамический, хронологический) ряд. Для дальнейшего прогнозирования необходимо подобрать аналитическую функцию (прямую или кривую), наиболее точно характеризующую закономерность развития данного явления или процесса во времени. Найденная функция позволяет получить выровненные значения уровней ряда динамики (его теоретические оценки), т.е. те уровни, которые наблюдались бы, если бы динамика явления или процесса полностью совпадала с выбранной кривой (линией регрессии).
Основными методами преобразования наблюдаемых статистических значений исследуемых показателей к аналитическому виду являются интерполяция, аппроксимация и экстраполяция (рис. 14).
Известно, что через любые n + 1 точки можно всегда провести кривую, описываемую полиномом n-й степени, так, чтобы она прошла через каждую из заданных точек а1, а2, ..., аn. Эта кривая называется интерполирующей, а процесс её нахождения - интерполяцией. Однако в практике моделирования производственно-экономических объектов применяются интерполяционные полиномы невысоких степеней (ввиду проблемы интерпретации сложных зависимостей), в первую очередь для вычисления промежуточных значений, отсутствующих в таблице. Простейшим случаем является линейная интерполяция, т.е. интерполяция функции f(х) линейной функцией F(х).

Рис. 14. Уравнение и линия тренда
Для получения более “гладкого” вида интерполирующей кривой при линейной интерполяции применяются формулы Ньютона. При параболической и квадратичной интерполяции полином второй степени используется формула Лагранжа. Программы интерполяции входят в стандартное математическое обеспечение ЭВМ.
Во многих случаях для функции, заданной таблично или графически, бывает целесообразно подобрать аналитическое выражение, приближенно её отражающее. Такой процесс называется приближенной интерполяцией или аппроксимацией. Для приближения заданной функции f(х) выбирают аппроксимирующую функцию F(х) из классов математических функций, в наибольшей степени соответствующих специфике протекания исследуемого процесса.
Наибольшее распространение в практике экономических исследований получили следующие функции:
линейная
![]() ;
;
степенная
![]() ;
;
экспоненциальная
![]() ;
;
показательная
![]() .
.
Процесс подбора эмпирической формулы для установленной из опыта функциональной зависимости является итерационным и распадается на две части: выбирается вид формулы; определяются числовые значения параметров, для которых приближение к данной функции оказывается наилучшим.
Для решения первой задачи по экспериментальным данным строятся графики, по которым и выбирается вид аппроксимирующей зависимости. Для решения второй задачи существует ряд методов приближения эмпирической кривой к экспериментальной, например, приближение по методу наименьших квадратов.
Особую роль вопросы экономного представления табличной информации в аналитическом виде играют при обработке статистической информации, в связи с чем в рамках математической статистики получили развитие разделы однофакторного и многофакторного регрессионного анализа. Программы обработки статистических данных методами регрессионного анализа также представлены в стандартном математическом обеспечении ЭВМ.
Экстраполяция - это продолжение интерполяции и аппроксимации за пределы диапазона статистических данных. Если исследуемый фактор - время, то это прогнозирование в будущее. Предположение, что действие различных факторов, обусловливающих явление в прошлом, остается неизменным в течение будущего периода или будет меняться в соответствии с расчетной кривой, позволяет прогнозировать это явление в будущем.
Прогнозная экстраполяция строится на основе математического анализа исходного ряда с учетом логики и существа развития объекта, его физики и абсолютных пределов.
Этапы прогнозной экстраполяции: предварительная обработка исходного ряда; выбор типа аппроксимирующей функции; расчет параметров аппроксимирующей функции; экстраполяционная оценка точности и достоверности результатов.
Для определения параметров уравнения регрессии используется метод наименьших квадратов, который требует, чтобы сумма квадратов отклонений значений, лежащих на линии регрессии (теоретических оценок уровней), от фактических значений уровней была минимальной, т.е. чтобы соблюдалось условие (yр – yф)2 min, где yф - фактическое значение уровня динамики, yр - теоретическая (расчетная) оценка уровня.
Аналитическим выражением прямолинейного тренда является функция
yt = b0 + b1 t,
где b0 и b1 - параметры уравнения регрессии; t - очередной номер уровня ряда с начала отсчета (номер временного периода).
Для определения параметров тренда необходимо решить систему нормальных уравнений
 yt
= b0
n
+ b1
t,
yt
= b0
n
+ b1
t,
yt t = b0 t + b1 t2,
где n - количество значений ряда динамики.
Произведя преобразования, получим:
b0 = ( yt – b1 t )/n,
b1 = (n yt t - t yt)/(nt2 - (t)2).
Коэффициент корреляции определяется по формуле:

где yt - фактическое значение показателя динамического ряда за t-й период (момент); yt - среднее значение показателей динамического ряда; t - условный номер t-го периода;t - средняя величина условных номеров периодов; n - количество наблюдений в ряду.
Интервал, в котором с определенной вероятностью можно ожидать появление фактического значения прогнозируемой величины, называется доверительным интервалом. Величина доверительного интервала зависит от среднеквадратической ошибки оценки прогнозируемого показателя (yt), от времени учреждения прогноза (Т) и от количества периодов наблюдения во временном ряду (n):

где yфt - фактическое значение показателя динамического ряда за t-й интервал (момент) времени; yрt - расчетная оценка показателя динамического ряда по уравнению регрессии; n - количество моментов во временном ряду; k - число параметров в уравнении регрессии.
Тогда для прямолинейного тренда доверительный интервал прогноза можно определить по формуле:
![]()
где Yn+T - прогноз на n+Т-й период времени; t;n-2 - значение критерия Стьюдента при уровне значимости и n-2 степенях свободы.
Пусть требуется определить прогнозную оценку некоторого показателя на три предстоящих месяца, имеется статистика изменения этого показателя за девять предшествующих месяцев:
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
59,319 |
68,921 |
74,088 |
91,125 |
97,336 |
103,823 |
125,0 |
140,608 |
148,877 |
После решения задачи на ЭВМ получим параметры уравнения регрессии, коэффициент корреляции и прогнозную оценку рассматриваемого показателя на соответствующий момент времени:
b0 = 43,69; b1 = 11,46; r = 0,98;
подставив в уравнение тренда значения t = 10; 11; 12, получим: Y10 = 158,33; Y11 = 169,79; Y12 = 181,256.
Для каждого полученного прогнозного значения необходимо рассчитать доверительный интервал.